Норма́льное распределе́ние[1][2], также называемое распределением Гаусса или Гаусса — Лапласа[3] — распределение вероятностей, которое в одномерном случае задаётся функцией плотности вероятности, совпадающей с функцией Гаусса:
| Нормальное распределение | |
|---|---|
 Зеленая линия соответствует стандартному нормальному распределениюПлотность вероятности |
|
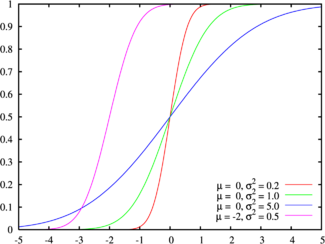 Цвета на этом графике соответствуют графику наверхуФункция распределения |
|
| Обозначение | N(μ,σ2){displaystyle Nleft(mu ,sigma ^{2}right)} |
| Параметры | μ — коэффициент сдвига (вещественный) σ > 0 — коэффициент масштаба (вещественный, строго положительный) |
| Носитель | x∈(−∞;+∞){displaystyle xin left(-infty ;+infty right)} |
| Плотность вероятности | 1σ2πexp(−(x−μ)22σ2){displaystyle {frac {1}{sigma {sqrt {2pi }}}};exp left(-{frac {left(x-mu right)^{2}}{2sigma ^{2}}}right)} |
| Функция распределения | 12[1+erf(x−μ2σ2)]{displaystyle {frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sqrt {2sigma ^{2}}}}right)right]} |
| Математическое ожидание | μ{displaystyle mu } |
| Медиана | μ{displaystyle mu } |
| Мода | μ{displaystyle mu } |
| Дисперсия | σ2{displaystyle sigma ^{2}} |
| Коэффициент асимметрии | 0{displaystyle 0} |
| Коэффициент эксцесса | 0{displaystyle 0} |
| Дифференциальная энтропия | ln(σ2πe){displaystyle ln left(sigma {sqrt {2,pi ,e}}right)} |
| Производящая функция моментов | MX(t)=exp(μt+σ2t22){displaystyle M_{X}left(tright)=exp left(mu ,t+{frac {sigma ^{2}t^{2}}{2}}right)} |
| Характеристическая функция | ϕX(t)=exp(μit−σ2t22){displaystyle phi _{X}left(tright)=exp left(mu ,i,t-{frac {sigma ^{2}t^{2}}{2}}right)} |



![{frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sqrt {2sigma ^{2}}}}right)right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/04670b14acb4ddb796469f3812ead9d9cccec275)






- f(x)=1σ2πe−(x−μ)22σ2,{displaystyle f(x)={frac {1}{sigma {sqrt {2pi }}}};e^{-{frac {(x-mu )^{2}}{2sigma ^{2}}}},}

где параметр μ{displaystyle mu } — математическое ожидание (среднее значение), медиана и мода распределения, а параметр σ{displaystyle sigma } — среднеквадратическое отклонение (σ2{displaystyle sigma ^{2}} — дисперсия) распределения.
 —
— Таким образом, одномерное нормальное распределение является двухпараметрическим семейством распределений, которое принадлежит экспоненциальному классу распределений.[4] Многомерный случай описан в статье «Многомерное нормальное распределение».
Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием μ=0{displaystyle mu =0} и стандартным отклонением σ=1{displaystyle sigma =1}.
 и стандартным отклонением σ=1{displaystyle sigma =1}
и стандартным отклонением σ=1{displaystyle sigma =1} .
.Содержание
- 1 Общие сведения
- 2 Определения
- 3 Свойства
- 4 Моделирование нормальных псевдослучайных величин
- 5 Нормальное распределение в природе и приложениях
- 6 Связь с другими распределениями
- 7 История
- 8 См. также
- 9 Примечания
- 10 Литература
- 11 Ссылки
Общие сведения
Если величина является суммой многих случайных слабо взаимозависимых величин, каждая из которых вносит малый вклад относительно общей суммы, то центрированное и нормированное распределение такой величины при достаточно большом числе слагаемых стремится к нормальному распределению.
Это следует из центральной предельной теоремы теории вероятностей. В окружающем нас мире часто встречаются величины, значение которых определяется совокупностью многих независимых факторов. Этот факт, а также то, что распределение считалось типичным, обычным, привели к тому, что в конце 19 века стал использоваться термин «нормальное распределение». Нормальное распределение играет заметную роль во многих областях науки, например в математической статистике и статистической физике.
Случайная величина, имеющая нормальное распределение, называется нормальной, или гауссовской, случайной величиной.
Определения
Стандартное нормальное распределение
Наиболее простой случай нормального распределения — стандартное нормальное распределение — частный случай, когда μ=0{displaystyle mu =0}
и σ=1{displaystyle sigma =1} . Его плотность вероятности равна
- φ(x)=12πe−12×2{displaystyle varphi (x)={frac {1}{sqrt {2pi }}}e^{-{frac {1}{2}}x^{2}}}

Множитель 12π{displaystyle {frac {1}{sqrt {2pi }}}}
в выражении обеспечивает условие нормировки интеграла ∫−∞+∞φ(x)dx{displaystyle int limits _{-infty }^{+infty }varphi (x),dx} .[5] Поскольку множитель 12{displaystyle {frac {1}{2}}} в экспоненте обеспечивает единичную дисперсию (то есть дисперсия равна единице), то и стандартное отклонение равно 1. Функция симметрична в точке x=0{displaystyle x=0} , её значение в ней максимально и равно 12π{displaystyle {frac {1}{sqrt {2pi }}}} . Точки перегиба функции — x=+1{displaystyle x=+1} и x=−1{displaystyle x=-1} .
 в выражении обеспечивает условие нормировки интеграла ∫−∞+∞φ(x)dx{displaystyle int limits _{-infty }^{+infty }varphi (x),dx}
в выражении обеспечивает условие нормировки интеграла ∫−∞+∞φ(x)dx{displaystyle int limits _{-infty }^{+infty }varphi (x),dx} .
. в экспоненте обеспечивает единичную дисперсию (то есть дисперсия равна единице), то и стандартное отклонение равно 1. Функция симметрична в точке x=0{displaystyle x=0}
в экспоненте обеспечивает единичную дисперсию (то есть дисперсия равна единице), то и стандартное отклонение равно 1. Функция симметрична в точке x=0{displaystyle x=0} , её значение в ней максимально и равно 12π{displaystyle {frac {1}{sqrt {2pi }}}}
, её значение в ней максимально и равно 12π{displaystyle {frac {1}{sqrt {2pi }}}} и x=−1{displaystyle x=-1}
и x=−1{displaystyle x=-1} .
.Гаусс называл стандартным нормальным распределение с σ2=1/2{displaystyle sigma ^{2}=1/2}
, то есть
 , то есть
, то есть- φ(x)=e−x2π.{displaystyle varphi (x)={frac {e^{-x^{2}}}{sqrt {pi }}}.}

Нормальное распределение с параметрами μ,σ{displaystyle mu ,sigma }

Каждое нормальное распределение — это вариант стандартного нормального распределения, область значений которого растягивается множителем σ{displaystyle sigma }
(стандартное отклонение) и переносится на μ{displaystyle mu } (математическое ожидание):
- f(x∣μ,σ2)=1σφ(x−μσ).{displaystyle f(xmid mu ,sigma ^{2})={frac {1}{sigma }}varphi left({frac {x-mu }{sigma }}right).}

μ,σ{displaystyle mu ,sigma }
являются параметрами нормального распределения. Плотность вероятности должна нормироваться 1σ{displaystyle {frac {1}{sigma }}} , так что интеграл равен 1.
 , так что интеграл равен 1.
, так что интеграл равен 1.Если Z{displaystyle Z}
— стандартная нормальная случайная величина, то величина X=σZ+μ{displaystyle X=sigma Z+mu } будет иметь нормальное распределение с математическим ожиданием μ{displaystyle mu } и стандартным отклонением σ{displaystyle sigma } . Наоборот, если X{displaystyle X} — нормальная величина с параметрами μ{displaystyle mu } и σ2{displaystyle sigma ^{2}} , то Z=X−μσ{displaystyle Z={frac {X-mu }{sigma }}} будет иметь стандартное нормальное распределение.
 — стандартная нормальная случайная величина, то величина X=σZ+μ{displaystyle X=sigma Z+mu }
— стандартная нормальная случайная величина, то величина X=σZ+μ{displaystyle X=sigma Z+mu } будет иметь нормальное распределение с математическим ожиданием μ{displaystyle mu }
будет иметь нормальное распределение с математическим ожиданием μ{displaystyle mu } — нормальная величина с параметрами μ{displaystyle mu }
— нормальная величина с параметрами μ{displaystyle mu } будет иметь стандартное нормальное распределение.
будет иметь стандартное нормальное распределение.Если в экспоненте плотности вероятности раскрыть скобки и учитывать, что 1=lne{displaystyle 1=ln e}
, то
 , то
, то- f(x)=1σ2πe−12(x−μσ)2=e−12(2lnσ+ln2π+(x−μσ)2)=e−12(x2σ2−2μxσ2+2lnσ+ln2π+μ2σ2){displaystyle f(x)={frac {1}{sigma {sqrt {2pi }}}}e^{-{frac {1}{2}}left({frac {x-mu }{sigma }}right)^{2}}=e^{-{frac {1}{2}}left(2ln sigma +ln 2pi +({frac {x-mu }{sigma }}right)^{2})}=e^{-{frac {1}{2}}left({frac {x^{2}}{sigma ^{2}}}-2{frac {mu x}{sigma ^{2}}}+2ln sigma +ln 2pi +{frac {mu ^{2}}{sigma ^{2}}}right)}}

Таким образом, плотность вероятности каждого нормального распределения представляет собой экспоненту квадратичной функции:
- f(x)=eax2+bx+c{displaystyle f(x)=e^{ax^{2}+bx+c}}

где a=−12σ2,b=μσ2,c=−(lnσ+12ln2π+12μ2σ2){displaystyle a=-{frac {1}{2sigma ^{2}}},b={frac {mu }{sigma ^{2}}},c=-(ln sigma +{frac {1}{2}}ln 2pi +{frac {1}{2}}{frac {mu ^{2}}{sigma ^{2}}})}
. Отсюда можно выразить среднее значение как μ=−b2a{displaystyle mu =-{frac {b}{2a}}} , а дисперсию как σ2=−12a{displaystyle sigma ^{2}=-{frac {1}{2a}}} . Для стандартного нормального распределения a=−1/2{displaystyle a=-1/2} , b=0{displaystyle b=0} и c=−12ln2π{displaystyle c=-{frac {1}{2}}ln 2pi } .
 . Отсюда можно выразить среднее значение как μ=−b2a{displaystyle mu =-{frac {b}{2a}}}
. Отсюда можно выразить среднее значение как μ=−b2a{displaystyle mu =-{frac {b}{2a}}} , а дисперсию как σ2=−12a{displaystyle sigma ^{2}=-{frac {1}{2a}}}
, а дисперсию как σ2=−12a{displaystyle sigma ^{2}=-{frac {1}{2a}}} . Для стандартного нормального распределения a=−1/2{displaystyle a=-1/2}
. Для стандартного нормального распределения a=−1/2{displaystyle a=-1/2} , b=0{displaystyle b=0}
, b=0{displaystyle b=0} и c=−12ln2π{displaystyle c=-{frac {1}{2}}ln 2pi }
и c=−12ln2π{displaystyle c=-{frac {1}{2}}ln 2pi } .
.Обозначение
Плотность вероятности стандартного нормального распределения (с нулевым средним и единичной дисперсией) часто обозначается греческой буквой ϕ{displaystyle phi }
(фи).[6] Также достаточно часто используется альтернативная формы греческой буквы фи φ{displaystyle varphi } .
 (
( .
.Нормальное распределение часто обозначается N(μ,σ2){displaystyle N(mu ,sigma ^{2})}
, или N(μ,σ2){displaystyle {mathcal {N}}(mu ,sigma ^{2})} .[7] Если случайная величина X{displaystyle X} распределена по нормальному закону со средним μ{displaystyle mu } и вариацией σ2{displaystyle sigma ^{2}} , то пишут
 , или N(μ,σ2){displaystyle {mathcal {N}}(mu ,sigma ^{2})}
, или N(μ,σ2){displaystyle {mathcal {N}}(mu ,sigma ^{2})} .
.- X∼N(μ,σ2).{displaystyle Xsim {mathcal {N}}(mu ,sigma ^{2}).}

Функция распределения
Функция распределения стандартного нормального распределения обычно обозначается заглавной греческой буквой Φ{displaystyle Phi }
(фи) и представляет собой интеграл
 (
(- Φ(x)=12π∫−∞xe−t2/2dt{displaystyle Phi (x)={frac {1}{sqrt {2pi }}}int limits _{-infty }^{x}e^{-t^{2}/2},dt}

С ней связана функция ошибок (интеграл вероятности) erf(x){displaystyle operatorname {erf} (x)}
, дающий вероятность того, что нормальная случайная величина со средним 0 и вариацией 1/2 попадёт в отрезок [−x,x]{displaystyle [-x,x]} :
 , дающий вероятность того, что нормальная случайная величина со средним 0 и вариацией 1/2 попадёт в отрезок [−x,x]{displaystyle [-x,x]}
, дающий вероятность того, что нормальная случайная величина со средним 0 и вариацией 1/2 попадёт в отрезок [−x,x]{displaystyle [-x,x]}![{displaystyle [-x,x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e23c41ff0bd6f01a0e27054c2b85819fcd08b762) :
:- erf(x)=2π∫0xe−t2dt{displaystyle operatorname {erf} (x)={frac {2}{sqrt {pi }}}int limits _{0}^{x}e^{-t^{2}},dt}

Эти интегралы неберущиеся в элементарных функциях и называются специальными фунциями. Многие их численные приближения известны. См. ниже.
Функции связаны, в частности соотношением
- Φ(x)=12[1+erf(x2)]{displaystyle Phi (x)={frac {1}{2}}left[1+operatorname {erf} left({frac {x}{sqrt {2}}}right)right]}
![{displaystyle Phi (x)={frac {1}{2}}left[1+operatorname {erf} left({frac {x}{sqrt {2}}}right)right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7831a9a5f630df7170fa805c186f4c53219ca36)
Нормальное распределение с плотностью f{displaystyle f}
, средним μ{displaystyle mu } и отклонением σ{displaystyle sigma } имеет следующую функцию распределения:
 , средним μ{displaystyle mu }
, средним μ{displaystyle mu }- F(x)=Φ(x−μσ)=12[1+erf(x−μσ2)]{displaystyle F(x)=Phi left({frac {x-mu }{sigma }}right)={frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sigma {sqrt {2}}}}right)right]}
![{displaystyle F(x)=Phi left({frac {x-mu }{sigma }}right)={frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sigma {sqrt {2}}}}right)right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/75deccfbc473d782dacb783f1524abb09b8135c0)
Можно использовать функцию Q(x)=1−Φ(x){displaystyle Q(x)=1-Phi (x)}
— она даст вероятность того, что значение стандартной нормальной случайной величины X{displaystyle X} превысит x{displaystyle x} : P(X>x){displaystyle P(X>x)} .
 — она даст вероятность того, что значение стандартной нормальной случайной величины X{displaystyle X}
— она даст вероятность того, что значение стандартной нормальной случайной величины X{displaystyle X} : P(X>x){displaystyle P(X>x)}
: P(X>x){displaystyle P(X>x)} .
.График стандартной нормальной функции распределения Φ{displaystyle Phi }
имеет 2-кратную вращательную симметрию относительно точки (0,1/2), то есть Φ(−x)=1−Φ(x){displaystyle Phi (-x)=1-Phi (x)} . Её неопределенный интеграл равен
 . Её неопределенный интеграл равен
. Её неопределенный интеграл равен- ∫Φ(x)dx=xΦ(x)+φ(x)+C.{displaystyle int Phi (x),dx=xPhi (x)+varphi (x)+C.}

Функция распределения стандартной нормальной случайной величины может быть разложена с помощью интегрирования по частям в ряд:
- Φ(x)=12+12π⋅e−x2/2[x+x33+x53⋅5+⋯+x2n+1(2n+1)!!+⋯]{displaystyle Phi (x)={frac {1}{2}}+{frac {1}{sqrt {2pi }}}cdot e^{-x^{2}/2}left[x+{frac {x^{3}}{3}}+{frac {x^{5}}{3cdot 5}}+cdots +{frac {x^{2n+1}}{(2n+1)!!}}+cdots right]}
![{displaystyle Phi (x)={frac {1}{2}}+{frac {1}{sqrt {2pi }}}cdot e^{-x^{2}/2}left[x+{frac {x^{3}}{3}}+{frac {x^{5}}{3cdot 5}}+cdots +{frac {x^{2n+1}}{(2n+1)!!}}+cdots right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/54d12af9a3b12a7f859e4e7be105d172b53bcfb8)
где знак !!{displaystyle !!}
означает двойной факториал.
 означает
означает Асимптотическое разложение функции распределения для больших x{displaystyle x}
может быть также произведено интегрированием по частям.
Стандартное отклонение
См. также: Интервальная оценка Для нормального распределения значения, отличающиеся от среднего на число, меньшее чем одно стандартное отклонение, составляют 68,27 % популяции. В то же время значения, отличающиеся от среднего на два стандартных отклонения, составляют 95,45 %, а на три стандартных отклонения — 99,73 %.
Для нормального распределения значения, отличающиеся от среднего на число, меньшее чем одно стандартное отклонение, составляют 68,27 % популяции. В то же время значения, отличающиеся от среднего на два стандартных отклонения, составляют 95,45 %, а на три стандартных отклонения — 99,73 %.
Около 68 % значений из нормального распределения находятся на расстоянии не более одного стандартного отклонения σ от среднего; около 95 % значений лежат расстоянии не более двух стандартных отклонений; и 99,7 % не более трёх. Этот факт является частным случаем правила 3 сигм для нормальной выборки.
Более точно, вероятность получить нормальное число в интервале между μ−nσ{displaystyle mu -nsigma }
и μ+nσ{displaystyle mu +nsigma } равна
 и μ+nσ{displaystyle mu +nsigma }
и μ+nσ{displaystyle mu +nsigma } равна
равна- F(μ+nσ)−F(μ−nσ)=Φ(n)−Φ(−n)=erf(n2).{displaystyle F(mu +nsigma )-F(mu -nsigma )=Phi (n)-Phi (-n)=operatorname {erf} left({frac {n}{sqrt {2}}}right).}

Если рассматривать 12 значимых символов, значения для n=1,2,…,6{displaystyle n=1,2,ldots ,6}
равны:[8]
 равны:
равны:| n{displaystyle n} | p=F(μ+nσ)−F(μ−nσ){displaystyle p=F(mu +nsigma )-F(mu -nsigma )} | 1−p{displaystyle 1-p} | 11−p{displaystyle {frac {1}{1-p}}} | OEIS | |
|---|---|---|---|---|---|
| 1 | 0.682689492137 | 0.317310507863 |
|
A178647 | |
| 2 | 0.954499736104 | 0.045500263896 |
|
A110894 | |
| 3 | 0.997300203937 | 0.002699796063 |
|
A270712 | |
| 4 | 0.999936657516 | 0.000063342484 |
|
||
| 5 | 0.999999426697 | 0.000000573303 |
|
||
| 6 | 0.999999998027 | 0.000000001973 |
|




Свойства
Моменты
Моментами и абсолютными моментами случайной величины X{displaystyle X}
называются математические ожидания случайных величин Xp{displaystyle X^{p}} и |X|p{displaystyle left|Xright|^{p}} , соответственно. Если математическое ожидание случайной величины μ=0{displaystyle mu =0} , то эти параметры называются центральными моментами. В большинстве случаев представляют интерес моменты для целых p{displaystyle p} .
 и |X|p{displaystyle left|Xright|^{p}}
и |X|p{displaystyle left|Xright|^{p}} , соответственно. Если математическое ожидание случайной величины μ=0{displaystyle mu =0}
, соответственно. Если математическое ожидание случайной величины μ=0{displaystyle mu =0} .
.Если X{displaystyle X}
имеет нормальное распределение, то для неё существуют (конечные) моменты при всех p{displaystyle p} с действительной частью больше −1. Для неотрицательных целых p{displaystyle p} , центральные моменты таковы:
- E[Xp]={0p=2n+1,σp(p−1)!!p=2n.{displaystyle mathrm {E} left[X^{p}right]={begin{cases}0&p=2n+1,sigma ^{p},left(p-1right)!!&p=2n.end{cases}}}
![mathrm {E} left[X^{p}right]={begin{cases}0&p=2n+1,sigma ^{p},left(p-1right)!!&p=2n.end{cases}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65f2b047b1a6f6f4bdaa1fa7269b41e90baddc6b)
Здесь n{displaystyle n}
— натуральное число, а запись (p−1)!!{displaystyle (p-1)!!} означает двойной факториал числа p−1{displaystyle p-1} , то есть (поскольку p−1{displaystyle p-1} в данном случае нечётно) произведение всех нечётных чисел от 1 до p−1{displaystyle p-1} .
 означает
означает  , то есть (поскольку p−1{displaystyle p-1}
, то есть (поскольку p−1{displaystyle p-1}Центральные абсолютные моменты для неотрицательных целых p{displaystyle p}
таковы:
- E[|X|p]=σp(p−1)!!⋅{2πp=2n+1,1p=2n.}=σp⋅2p2Γ(p+12)π.{displaystyle operatorname {E} left[left|Xright|^{p}right]=sigma ^{p},left(p-1right)!!cdot left.{begin{cases}{sqrt {frac {2}{pi }}}&p=2n+1,1&p=2n.end{cases}}right}=sigma ^{p}cdot {frac {2^{frac {p}{2}}Gamma left({frac {p+1}{2}}right)}{sqrt {pi }}}.}
![operatorname {E} left[left|Xright|^{p}right]=sigma ^{p},left(p-1right)!!cdot left.{begin{cases}{sqrt {frac {2}{pi }}}&p=2n+1,1&p=2n.end{cases}}right}=sigma ^{p}cdot {frac {2^{frac {p}{2}}Gamma left({frac {p+1}{2}}right)}{sqrt {pi }}}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/55ec6aa1a10f009e0d83a9aad4dc92ae65ab0c11)
Последняя формула справедлива также для произвольных p>−1{displaystyle p>-1}
.
 .
.Преобразование Фурье и характеристическая функция
Преобразование Фурье нормальной плотности вероятности f{displaystyle f}
с математическим ожиданием μ{displaystyle mu } стандартным отклонением σ{displaystyle sigma } равно[9]
- f^(t)=∫−∞∞f(x)e−itxdx=e−iμte−12(σt)2{displaystyle {hat {f}}(t)=int limits _{-infty }^{infty }f(x)e^{-itx},dx=e^{-imu t}e^{-{frac {1}{2}}(sigma t)^{2}}}

где i{displaystyle i}
есть мнимая единица. Если математическое ожидание μ=0{displaystyle mu =0} , то первый множитель равен 1, и преобразование Фурье, не считая константу, есть нормальная плотность вероятности на частотных интервалах, с математическим ожиданием равным 0 и стандартным отклонением 1/σ{displaystyle 1/sigma } . В частности, стандартное нормальное распределение φ{displaystyle varphi } есть собственная функция от преобразования Фурье.
 есть
есть  . В частности, стандартное нормальное распределение φ{displaystyle varphi }
. В частности, стандартное нормальное распределение φ{displaystyle varphi }В теории вероятности, преобразование Фурье плотности распределения действительной случайной величины X{displaystyle X}
близко связано с характеристической функцией φX(t){displaystyle varphi _{X}(t)} этой величины, которая определена как математическое ожидание от eitX{displaystyle e^{itX}} и является функцией вещественной переменной t{displaystyle t} (частотный параметр преобразования Фурье). Определение может быть распространено и на комплексную переменную t{displaystyle t} .[10] Соотношение записывается так:
 этой величины, которая определена как
этой величины, которая определена как  и является функцией вещественной переменной t{displaystyle t}
и является функцией вещественной переменной t{displaystyle t} (частотный параметр преобразования Фурье). Определение может быть распространено и на комплексную переменную t{displaystyle t}
(частотный параметр преобразования Фурье). Определение может быть распространено и на комплексную переменную t{displaystyle t}- φX(t)=f^(−t){displaystyle varphi _{X}(t)={hat {f}}(-t)}

Бесконечная делимость
Нормальное распределение является бесконечно делимым.
Если случайные величины X1{displaystyle X_{1}}
и X2{displaystyle X_{2}} независимы и имеют нормальное распределение с математическими ожиданиями μ1{displaystyle mu _{1}} и μ2{displaystyle mu _{2}} и дисперсиями σ12{displaystyle sigma _{1}^{2}} и σ22{displaystyle sigma _{2}^{2}} соответственно, то X1+X2{displaystyle X_{1}+X_{2}} также имеет нормальное распределение с математическим ожиданием μ1+μ2{displaystyle mu _{1}+mu _{2}} и дисперсией σ12+σ22.{displaystyle sigma _{1}^{2}+sigma _{2}^{2}.} Отсюда вытекает, что нормальная случайная величина представима как сумма произвольного числа независимых нормальных случайных величин.
 и X2{displaystyle X_{2}}
и X2{displaystyle X_{2}} независимы и имеют нормальное распределение с математическими ожиданиями μ1{displaystyle mu _{1}}
независимы и имеют нормальное распределение с математическими ожиданиями μ1{displaystyle mu _{1}} и μ2{displaystyle mu _{2}}
и μ2{displaystyle mu _{2}} и дисперсиями σ12{displaystyle sigma _{1}^{2}}
и дисперсиями σ12{displaystyle sigma _{1}^{2}} и σ22{displaystyle sigma _{2}^{2}}
и σ22{displaystyle sigma _{2}^{2}} соответственно, то X1+X2{displaystyle X_{1}+X_{2}}
соответственно, то X1+X2{displaystyle X_{1}+X_{2}} также имеет нормальное распределение с математическим ожиданием μ1+μ2{displaystyle mu _{1}+mu _{2}}
также имеет нормальное распределение с математическим ожиданием μ1+μ2{displaystyle mu _{1}+mu _{2}} и дисперсией σ12+σ22.{displaystyle sigma _{1}^{2}+sigma _{2}^{2}.}
и дисперсией σ12+σ22.{displaystyle sigma _{1}^{2}+sigma _{2}^{2}.} Отсюда вытекает, что нормальная случайная величина представима как сумма произвольного числа независимых нормальных случайных величин.
Отсюда вытекает, что нормальная случайная величина представима как сумма произвольного числа независимых нормальных случайных величин.Максимальная энтропия
Нормальное распределение имеет максимальную дифференциальную энтропию среди всех непрерывных распределений, дисперсия которых не превышает заданную величину[11][12].
Правило трёх сигм для гауссовской случайной величины
Основная статья: Правило трёх сигм.svg) График плотности вероятности нормального распределения и процент попадания случайной величины на отрезки, равные среднеквадратическому отклонению.
График плотности вероятности нормального распределения и процент попадания случайной величины на отрезки, равные среднеквадратическому отклонению.
Правило трёх сигм (3σ{displaystyle 3sigma }
) — практически все значения нормально распределённой случайной величины лежат в интервале (μ−3σ;μ+3σ){displaystyle left(mu -3sigma ;mu +3sigma right)} , где μ=Eξ{displaystyle mu =Exi } — математическое ожидание и параметр нормальной случайной величины. Более точно — приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале.
 ) — практически все значения
) — практически все значения  , где μ=Eξ{displaystyle mu =Exi }
, где μ=Eξ{displaystyle mu =Exi } — математическое ожидание и параметр нормальной случайной величины. Более точно — приблизительно с вероятностью 0,9973 значение
— математическое ожидание и параметр нормальной случайной величины. Более точно — приблизительно с вероятностью 0,9973 значение Моделирование нормальных псевдослучайных величин
При компьютерном моделировании, особенно при применении метода Монте-Карло, желательно использовать величины, распределенные по нормальному закону. Многие алгоритмы дают стандартные нормальные величины, так как нормальную величину X∼N(μ,σ2){displaystyle Xsim N(mu ,sigma ^{2})}
можно получить как X=μ+σZ{displaystyle X=mu +sigma Z} , где Z — стандартная нормальная величина. Алгоритмы также используют различные преобразования равномерных величин.Простейшие приближённые методы моделирования основываются на центральной предельной теореме. Если сложить достаточно большое количество независимых одинаково распределённых величин с конечной дисперсией, то сумма будет иметь распределение, близкое к нормальному. Например, если сложить 100 независимых стандартно равномерно распределённых случайных величин, то распределение суммы будет приближённо нормальным.
 можно получить как X=μ+σZ{displaystyle X=mu +sigma Z}
можно получить как X=μ+σZ{displaystyle X=mu +sigma Z} , где Z — стандартная нормальная величина. Алгоритмы также используют различные преобразования равномерных величин.Простейшие приближённые методы моделирования основываются на
, где Z — стандартная нормальная величина. Алгоритмы также используют различные преобразования равномерных величин.Простейшие приближённые методы моделирования основываются на Для программного генерирования нормально распределённых псевдослучайных величин предпочтительнее использовать преобразование Бокса — Мюллера. Оно позволяет генерировать одну нормально распределённую величину на базе одной равномерно распределённой.
Также существует алгоритм Зиккурат, который работает даже быстрее преобразования Бокса — Мюллера. Тем не менее, сложнее в реализации, но его применение оправдано в случаях, когда требуется генерирование очень большого числа неравномерно распределённых случайных чисел.
Нормальное распределение в природе и приложениях
Нормальное распределение часто встречается в природе. Например, следующие случайные величины хорошо моделируются нормальным распределением:
- отклонение при стрельбе;
- погрешности измерений (однако погрешности некоторых измерительных приборов имеют иное распределение);
- некоторые характеристики живых организмов в популяции.
Такое широкое распространение этого распределения связано с тем, что оно является бесконечно делимым непрерывным распределением с конечной дисперсией. Поэтому к нему в пределе приближаются некоторые другие, например биномиальное и пуассоновское. Этим распределением моделируются многие недетерминированные физические процессы[13].
Многомерное нормальное распределение используется при исследовании многомерных случайных величин (случайных векторов). Одним из многочисленных примеров таких приложений является исследование параметров личности человека в психологии и психиатрии.
Связь с другими распределениями
- Нормальное распределение является распределением Пирсона типа XI[14].
- Отношение пары независимых стандартных нормально распределенных случайных величин имеет распределение Коши[15]. То есть, если случайная величина X{displaystyle X} представляет собой отношение X=Y/Z{displaystyle X=Y/Z} (где Y{displaystyle Y} и Z{displaystyle Z} — независимые стандартные нормальные случайные величины), то она будет обладать распределением Коши.
- Если z1,…,zk{displaystyle z_{1},ldots ,z_{k}} — совместно независимые стандартные нормальные случайные величины, то есть zi∼N(0,1){displaystyle z_{i}sim Nleft(0,1right)} , то случайная величина x=z12+…+zk2{displaystyle x=z_{1}^{2}+ldots +z_{k}^{2}} имеет распределение хи-квадрат с k степенями свободы.
- Если случайная величина X{displaystyle X} подчинена логнормальному распределению, то её натуральный логарифм имеет нормальное распределение. То есть, если X∼LogN(μ,σ2){displaystyle Xsim mathrm {LogN} left(mu ,sigma ^{2}right)} , то Y=ln(X)∼N(μ,σ2){displaystyle Y=ln left(Xright)sim mathrm {N} left(mu ,sigma ^{2}right)} . И наоборот, если Y∼N(μ,σ2){displaystyle Ysim mathrm {N} left(mu ,sigma ^{2}right)} , то X=exp(Y)∼LogN(μ,σ2){displaystyle X=exp left(Yright)sim mathrm {LogN} left(mu ,sigma ^{2}right)} .
- Если X1,X2,…,Xn{displaystyle X_{1},X_{2},…,X_{n}} независимые нормально распределенные случайные величины с математическими ожиданиями μ{displaystyle mu } и дисперсиями σ2{displaystyle sigma ^{2}} , то их выборочное среднее независимо от выборочного стандартного отклонения,[16] а отношение следующих двух величин будет иметь t-распределение с n−1{displaystyle {text{n}}-1} степенями свободы:
 (где Y{displaystyle Y}
(где Y{displaystyle Y} и Z{displaystyle Z}
и Z{displaystyle Z} — совместно независимые стандартные нормальные случайные величины, то есть zi∼N(0,1){displaystyle z_{i}sim Nleft(0,1right)}
— совместно независимые стандартные нормальные случайные величины, то есть zi∼N(0,1){displaystyle z_{i}sim Nleft(0,1right)} , то случайная величина x=z12+…+zk2{displaystyle x=z_{1}^{2}+ldots +z_{k}^{2}}
, то случайная величина x=z12+…+zk2{displaystyle x=z_{1}^{2}+ldots +z_{k}^{2}} имеет
имеет  , то Y=ln(X)∼N(μ,σ2){displaystyle Y=ln left(Xright)sim mathrm {N} left(mu ,sigma ^{2}right)}
, то Y=ln(X)∼N(μ,σ2){displaystyle Y=ln left(Xright)sim mathrm {N} left(mu ,sigma ^{2}right)} . И наоборот, если Y∼N(μ,σ2){displaystyle Ysim mathrm {N} left(mu ,sigma ^{2}right)}
. И наоборот, если Y∼N(μ,σ2){displaystyle Ysim mathrm {N} left(mu ,sigma ^{2}right)} , то X=exp(Y)∼LogN(μ,σ2){displaystyle X=exp left(Yright)sim mathrm {LogN} left(mu ,sigma ^{2}right)}
, то X=exp(Y)∼LogN(μ,σ2){displaystyle X=exp left(Yright)sim mathrm {LogN} left(mu ,sigma ^{2}right)} .
. независимые нормально распределенные случайные величины с математическими ожиданиями μ{displaystyle mu }
независимые нормально распределенные случайные величины с математическими ожиданиями μ{displaystyle mu } степенями свободы:
степенями свободы:-
- t=X¯−μS/n=1n(X1+⋯+Xn)−μ1n(n−1)[(X1−X¯)2+⋯+(Xn−X¯)2]∼tn−1.{displaystyle t={frac {{overline {X}}-mu }{S/{sqrt {n}}}}={frac {{frac {1}{n}}(X_{1}+cdots +X_{n})-mu }{sqrt {{frac {1}{n(n-1)}}left[(X_{1}-{overline {X}})^{2}+cdots +(X_{n}-{overline {X}})^{2}right]}}}sim t_{n-1}.}
![{displaystyle t={frac {{overline {X}}-mu }{S/{sqrt {n}}}}={frac {{frac {1}{n}}(X_{1}+cdots +X_{n})-mu }{sqrt {{frac {1}{n(n-1)}}left[(X_{1}-{overline {X}})^{2}+cdots +(X_{n}-{overline {X}})^{2}right]}}}sim t_{n-1}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/36ff0d3c79a0504e8f259ef99192b825357914d7)
- Если X1,X2,…,Xn{displaystyle X_{1},X_{2},…,X_{n}} , Y1,Y2,…,Yn{displaystyle Y_{1},Y_{2},…,Y_{n}} независимые стандартные нормальные случайные величины, то отношение нормированных сумм квадратов будет иметь распределение Фишера с (n{displaystyle {text{n}}} , m{displaystyle {text{m}}} ) степенями свободы:[17]
 независимые стандартные нормальные случайные величины, то отношение нормированных сумм квадратов будет иметь
независимые стандартные нормальные случайные величины, то отношение нормированных сумм квадратов будет иметь  , m{displaystyle {text{m}}}
, m{displaystyle {text{m}}} ) степенями свободы:
) степенями свободы:-
- F=(X12+X22+⋯+Xn2)/n(Y12+Y22+⋯+Ym2)/m∼Fn,m.{displaystyle F={frac {left(X_{1}^{2}+X_{2}^{2}+cdots +X_{n}^{2}right)/n}{left(Y_{1}^{2}+Y_{2}^{2}+cdots +Y_{m}^{2}right)/m}}sim F_{n,m}.}

- Отношение квадратов двух стандартных нормальных случайных величин имеет распределение Фишера со степенями свободы (1,1){displaystyle left(1,1right)} .
 .
.История
Впервые нормальное распределение как предел биномиального распределения при p=12{displaystyle p={tfrac {1}{2}}}
появилось в 1738 году во втором издании работы Муавра «Доктрина случайностей»[en][18]. Это было первое доказательство частного случая центральной предельной теоремы. В 1809 году Гаусс в сочинении «Теория движения небесных тел» ввёл это распределение как возникающее в результате многократных измерений движения небесных тел. Однако Гаусс вывел формулу для действительных случайных величин из принципа достижения максимума совместной плотности всех измерений в точке с координатами, равными среднему всех измерений. Этот принцип впоследствии подвергался критике. В 1812 году Лаплас в теореме Муавра — Лапласа обобщил результат Муавра для произвольного биномиального распределения, то есть для сумм одинаково распределённых независимых бинарных величин[3].
 появилось в 1738 году во втором издании работы
появилось в 1738 году во втором издании работы См. также
- Аддитивный белый гауссовский шум
- Логнормальное распределение
- Равномерное распределение
- Центральная предельная теорема
- Двумерное нормальное распределение
- Многомерное нормальное распределение
- Распределение хи-квадрат
- Статистический критерий
- Частотное распределение
Примечания
- ↑ Вентцель Е. С. Теория вероятностей. — 10-е изд., стер.. — М.: Academia, 2005. — 576 с. — ISBN 5-7695-2311-5.
- ↑ Ширяев, А. Н. Вероятность. — М.: Наука, 1980.
- ↑ 1 2 Математический энциклопедический словарь. — М.: Советская энциклопедия, 1988. — С. 139—140.
- ↑ L. Wasserman. All of Statistics. — New York, NY: Springer, 2004. — С. 142. — 433 с. — ISBN 978-1-4419-2322-6.
- ↑ Доказательство см. Гауссов интеграл
- ↑ Halperin, Hartley & Hoel (1965, 7)
- ↑ McPherson (1990)
- ↑ Wolfram|Alpha: Computational Knowledge Engine (неопр.). Wolframalpha.com. Дата обращения: 3 марта 2017.
- ↑ Bryc (1995, p. 23)
- ↑ Bryc (1995, p. 24)
- ↑ Cover, Thomas M.; Thomas, Joy A. Elements of Information Theory (неопр.). — John Wiley and Sons, 2006. — С. 254.
- ↑ Park, Sung Y.; Bera, Anil K. Maximum Entropy Autoregressive Conditional Heteroskedasticity Model (англ.) // Journal of Econometrics (англ.) (рус. : journal. — Elsevier, 2009. — P. 219—230. Архивировано 7 марта 2016 года.
- ↑ Талеб Н. Н. Чёрный лебедь. Под знаком непредсказуемости = The Black Swan: The Impact of the Highly Improbable. — КоЛибри, 2012. — 525 с. — ISBN 978-5-389-00573-0.
- ↑ Королюк, 1985, с. 135.
- ↑ Галкин В. М., Ерофеева Л. Н., Лещева С. В. Оценки параметра распределения Коши // Труды Нижегородского государственного технического университета им. Р. Е. Алексеева. — 2014. — № 2(104). — С. 314—319. — УДК 513.015.2(G).
- ↑ Lukacs, Eugene. A Characterization of the Normal Distribution (англ.) // The Annals of Mathematical Statistics (англ.) (рус. : journal. — 1942. — Vol. 13, no. 1. — P. 91—3. — ISSN 0003-4851. — doi:10.1214/aoms/1177731647. — JSTOR 2236166.
- ↑ Lehmann, E. L. Testing Statistical Hypotheses (неопр.). — 2nd. — Springer (англ.) (рус., 1997. — С. 199. — ISBN 978-0-387-94919-2.
- ↑ The doctrine of chances; or, a method of calculating the probability of events in play, L., 1718, 1738, 1756; L., 1967 (репродуцир. изд.); Miscellanea analytica de scriebus et quadraturis, L., 1730.
Литература
- Королюк В. С., Портенко Н. И., Скороход А. В., Турбин А. Ф. Справочник по теории вероятностей и математической статистике. — М.: Наука, 1985. — 640 с.
- Halperin, Max; Hartley, Herman O.; Hoel, Paul G. Recommended Standards for Statistical Symbols and Notation. COPSS Committee on Symbols and Notation (англ.) // The American Statistician (англ.) (рус. : journal. — 1965. — Vol. 19, no. 3. — P. 12—14. — doi:10.2307/2681417. — JSTOR 2681417.
- McPherson, Glen. Statistics in Scientific Investigation: Its Basis, Application and Interpretation (англ.). — Springer-Verlag, 1990. — ISBN 978-0-387-97137-7.
- Bryc, Wlodzimierz. The Normal Distribution: Characterizations with Applications (англ.). — Springer-Verlag, 1995. — ISBN 978-0-387-97990-8.
Ссылки
- Таблица значений функции стандартного нормального распределения
- Онлайн расчёт вероятности нормального распределения
| В другом языковом разделе есть более полная статья Normal distribution (англ.). Вы можете помочь проекту, расширив текущую статью с помощью перевода |
Для улучшения этой статьи желательно:
После исправления проблемы исключите её из списка. Удалите шаблон, если устранены все недостатки. |
